暇なので・・・・なんだか最近書いた自分の記事をGoogleで検索してみたのですが、ヒットしない・・・・
単純に『たーさま』で検索するとこのブログは先頭に表示されるのですが、タイトルの下に表示される概要が3月中旬のころのまま。
うーむ。
別に広告とか一切出していないこのブログは、完全に趣味の世界での運用であるので、お金儲けをしている人々のように目の色を変える必要はないのですが、技術的興味から調査開始。
Google側でどのように認識されているのかな? 以前ちょっとだけ触って完全放置プレーの『Googleアナリティクス』は・・・・サイトに訪れた人の行動を解析するツールであって、サイトを訪れる前の部分は関係ないみたい。
https://…/2017/08/15/ はてなカウンター廃止なので、Googleアナリティクスを使ってみよう
もう一つの『Googleサーチコンソール』がサイトに訪れる前の部分を操作するツールなのですが、以前一度起動した際に『独自ドメイン』でないと使用できないとかで、コレも放置プレー・・・・
しかし今開いてみたら、このブログのような共有ドメインで一定のURL配下にのみ所有権を持っている場合でも使用可能なように機能更新されていたので、早速登録してみました。
 |
| ・Googleサーチコンソール |
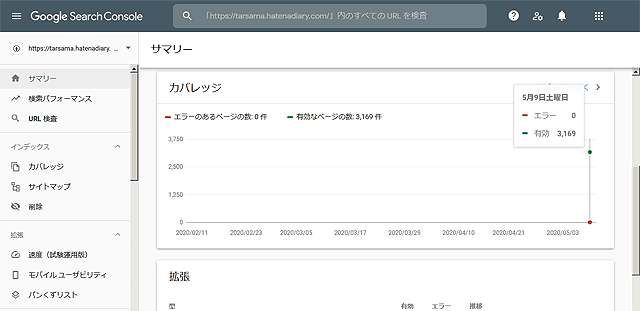
すると・・・・Google側で認識しているページの総数が3,169ですって。私の記事は5,800くらいあるはずなのに・・・・なにかあるぞ!?
このツール、Googleクローラー(Webを巡って情報を集めるプログラム。)がいつ・どんな情報を集めたのか、あるいはエラーで集めなかったのかといった事後情報を確認したり、あるいは『このページをクロールして』とリクエストを出せるみたい。
なになに、それでは情報の分析をしてみよう。
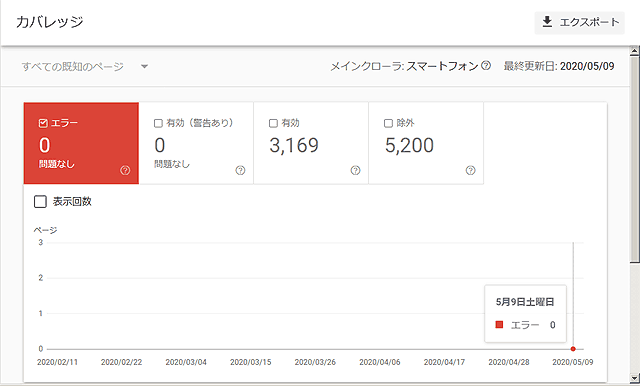 |
| ・ガバレッジ・・・・Googleクロールの結果 |
おやっ、除外ページが5,200もあるぞ!
その除外ページの詳細も確認することができます。なになに・・・・
 |
| ・除外ページの詳細 |
クロールされていながらインデックス(Googleの検索結果の元となるデータ)に登録されていないのが4,006!?
どういうことだ?
どのURLが該当するのかまで確認可能。すげぇなぁGoogle。
詳しく調べていくと・・・・『重複している』と判断された場合に除外される模様。
例えば日記一つごとのURLは『//tarsama.hatenadiary.com/entry/YYYYMMDD』形式となることが多いのですが、例えばその日一日を俯瞰する『//tarsama.hatenadiary.com/entries/YYYY/MM/DD/』とか、月を俯瞰するとか、カテゴリー一覧とかのページは同じ記事を表示しているだけなので除外するというわけか。
昔のクローラーは、とにかくリンクをたどっていくだけというパターンでしたが、今は中身の重複までチェックするのか・・・・
そして気になるデータを発見。
 |
| ・トップページが除外されている! |
なんとトップページが除外判定されている! それも3月18日を最後に! これで最近検索されない件と理屈は符号したぞ。
しかしトップページを見てくれなくなるということは、その先の最新の日記も見てくれないし、それ以外にも結構日記そのものも除外されているゾ?
試しにひとつクロールリクエストを送信したら、やがて登録済みになった・・・・
うそ~、コレ一つ一つ手動で中身をチェックして登録していくの?無理だ~
代わりにサイトマップを登録する手があるみたいなので、コレでしばらく様子を見てみることにします。
なんか、複雑になりすぎて大変な時代なったんだな・・・・